
How we work
Development Team Agreements
version 2.3
http://bit.ly/dev-how-we-work
http://bit.ly/dev-how-we-work

1. Intro
This document presents a set of objectives for the development team. It extends the Agile Workflow “affection”.TL;DR
- Please have a look at the tasks and ask questions there if you don't understand something.
- Be responsive on the trello and on chat.
- Rule of thumb: communicate!
- Try to start each task in a new branch. Try to push it to the repo and ask others who are related to that changeset to share comments if everything is OK (remember: the rule of thumb is to communicate).
- Once finished you make a PR to merge it into master. To merge it you need to have an approval from a reviewer and make sure all tasks are resolved.
- If you have a doubt then chat about it (using chat app or comment in Trello task).
- If you don't understand something then chat about it (as above).
- If you want to propose something you chat about it.
- We are using trello for tasks. All work should have a related task.
- For documentation we are using Notion (primary) and Trello for more detailed - task related communication.
2. Extreme Programming
We will practice Agile Extreme Programming.3. Agenda | Sprint
- Bi-weekly (or weekly) sprint planning: Monday morning.
- Daily updates. Every day when you start work.
Everybody, every working day, when starting work MUST post in #dev-daily-updates channel a message with the following pattern: What I have done. What I’m doing / plan to do. What are the blockers. Optionally you can share "What I found interesting". Also you have to update the task board. - Keep on track with the sprint plan.
- Always check the task board (trello) and update once you achieve something. Comment if something is badly designed, doesn’t work, there is a blocker or when something is just great!
- Work principles: Be proactive. Measure. Communicate!
- Sprint review at the end of each sprint, Friday morning.
- With every second sprint review we will have retrospective.
4. Communication and collaboration
In a distributed environment communication is crucial. Without good communication we will experience bad processes. To ensure a good communication, all team members consent to:- Be open — always inform your colleagues about your issues, when do you finish your work, when they can count on you. Always inform about non-default schedules.
It’s normal that you have private things to do. But don’t hide it. Others may expect something from you. Let them know that you won’t be available (if it’s something longer). - Plan — if you have impediments, issues or something which puts the delivery into a risk - plan it. Be proactive. Think about it. Discuss it. Best if you can propose some preliminary solutions.
- Be honest! This is very important. We can’t plan or communicate well if you are not honest. If you have a big problem -- let us know. Otherwise we will fail to make a plan and work as a team. Remember the team performance depends on you.
- If you have a personal issue — talk about it with the team manager. It’s better to solve things together.
- Be responsible.
- Provide daily updates (stand-up). Each morning, when you start a work you communicate in 3 paragraphs:
- What have you done.
- What are you planning to do.
- What is blocking you, what’s not clear or what problems are you encountering.
- Even if you didn’t do much - commit and push your changes.
- Every day update the task board. Move tasks or put comments.
Working together with a code.
If some feature development is dependent on another task which is work-in-progress, then don’t hesitate to do it in a single branch. It’s fair (and it’s part of git design) to allow multiple people to work on a single branch. This is crucial when you have an important task, and someone wants to collaborate, review and get your updates. Make it easy to allow others to collaborate.5. Development Flow
- All code resides in a repository assigned to the project.
- Make sure that all linters work.
- Make sure that all code hooks (git hooks) work.
- Follow the tasks.
- You should always have some ongoing task.
- All your ongoing tasks must have an estimated due date.
- Don’t hesitate to create new tasks - put them in the icebox (defined in FAQ below).
- Create a task for every feature / bug / ticket.
- Focus on your current tasks. Whenever you will find new things to do, just add a task to the icebox section instead of losing focus of a current task. We will plan it later.
- Communicate early and openly! Start from solution design before coding any complex task and present it. Make a functional review (no code review) for each bigger feature (>= 2 days) early - like in ⅓ of the work, where you will share your design and algorithm.
-
Gitlab flow
- All features should be in branch
- Create meaningful names to your branch
- Always assign a reviewer to your code when doing pull-request (PR)
- Keep the features small and create PRs often (ideally 1-3 days, max 4-5 days).
- All packages / projects have to have integrated linters and test framework.
- We start each new API related task with a blueprint design. Even when the API design is not ready, push it (in a branch) and get an early review! Say that it’s blocking. We prefer to spend more time on the design rather than spending too much time on rewrite.
For GraphQL - use GraphQL spec as a blueprint.
For REST API:- Frontend can use API Blueprint mock server to use it when implementing the frontend features before waiting for the backend.
- Backend should validate the response with the API Blueprint
- We use Snowboard as the rendering engine (documentation) and mock server.
- Make sure your editor has configured editorconfig support. The repositories contain .editorconfig file and it should be well respected.
- All feature / bug / ticket implementations should have corresponding tests. It is required that each new feature will have:
- unit test for all critical computation parts (frontend model and all backend packages)
- module test for backend functionality covering real world scenarios.
- All code in the master branch must:
- Pass all tests
- Pass all linters
- Be well structured
- Take care about code quality. Check the sections below:
- What we use to preserve good code style
- What is a filename convention
- Choose wisely about function / variable names. Look below at Code Style. What is a good name? What's in a name?. More - check below
- Master branch is untouchable! Only merges from feature / hotfix branches are allowed.
- Implement all features in branches
- You can't rebase master and hotfix branches. You can rebase feature branches.
- Each application should have a README file which provide:
- Explain application purpose
- List all dependencies
- Explain the privacy / security mode (who and how can use it)
- Runtime requirements: can it scale, how it should be run, what are minimum computing resources required (memory, cpu, …).
- Links to the application design documents (if any).
- Installation instructions.
Frontend
- Don't overdo things.
- Try to reuse existing components. Especially, try to reuse the framework components and customize them natively (don't wrap - customize the theme).
- Minimize the amount of styles created.
- Create standards over style copy-paste.
- Make everything testable.
- Follow the code organization.
6. Code Review
The overall aim of the code review process is to increase the quality of the codebase.Pull requests
When you finish implementing a feature, make a pull request and ask someone for code review.- Before creating a PR, make sure the source code is well organized and clean.
- Add reviewers (minimum 1), best if at least one is knowledgeable about the changeset.
- Tick “Close branch”, to automatically close a branch once it's merged (Bitbucket).
- Merge only when all PR tasks are resolved and all responses to comments provided.
- Focus on finishing current PR. It should never stay open for a long time.
- If you have questions ask openly
- If you wait - ping people you depend on
- Inform about any obstacles.
- Last, but not least: our methodology is to deliver step by step
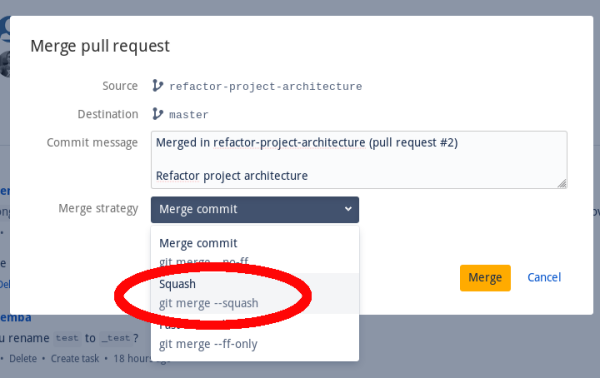
- Before merging squash not-relevant commits. In essence in most of the cases you should end up with only one commit. Bitbucket, Github and others provide a feature for that when merging the PR (image below).
- Merging should be possible only if there is an approval quorum between reviewers.
Reviewer Guidelines
Don't ask: 'does it work?' but 'is it easy to understand?' and 'is it simple?'It is not the responsibility of the code reviewer to ensure that there are no bugs before code is committed, nor even that the code functions at all. These are 100% the responsibility of the person submitting the code. If the reviewer wants to undertake these checks then that is great, but beyond what we expect of code reviewing.
The code reviewer should primarily assess the maintainability of the code submitted, which means asking the following basic questions:- Is it easy to understand? (could it be made easier to understand?)
- Does it follow best practices? (below)
- Is it well-documented?
- Does it follow code conventions?
The enemy of both code maintenance and code robustness is complexity. Your task as code reviewer is to find complexity and complain about it.
The code reviewer can also assess by inspection other important aspects of the code, such as:- modularity
- resource efficiency
Best Practices
There is a huge amount of advice regarding best practices, for example at: javapractices.com. We can't expect that submitted code is checked against all best practices. Here, for emphasis, are what we regard as the most important issues:Length of code
Probably the most important issues to look at relate to code length:- class size - look at the largest class: could it usefully be split into several smaller classes?
- method length - look out for method definitions consisting of many lines of code. It is likely that refactoring these into smaller methods could improve the ability of someone new understanding what the code is doing.
Code organization
Another issue can be package structure. Each class should be organized into a comprehensible package structure. There shouldn't be too many packages, nor too few. As a rough guide, if a package contains less than 4 or more than 10 classes, it may be worth rethinking.Naming
Another very important issue which is often under-rated is naming. Are packages, classes, methods and variables in your view, optimally named? Choose good names for the code!- Do you understand all the names?
- Do the class and method names express their purposes well?
- Sometimes short names are good
- Watch: What's in a name?
Code Style
All pushed code should confirm to the code style:- Default max code line length is 96. To visualize it you can use
- In Emacs: fill-mode, or FillColumnIndicator plugin.
gofmtandrevivefor.gofiles.Standard.jsfor JavaScriptpylintfor .py files.- max_line_length should be 96.
- High-level code should be self explained.
- properly configure of your favourite editor
- load programming languages plug-ins for your favourite editor (they should take care about automatic indentation)
- activate
git hooks. More info about them in project INSTALL.sh file
Code comments & docs style
Code is our common good.- All the style is verified by lint tools (yes it works also for comments).
- Comments should be compact and readable.
- TODO, FIXME sections should be linked with corresponding tasks on Task Management Tool.
- Good code brings better info than any comments.
- Prefer good functions, variable names then explaining cryptic things. Of course you can use short variables.
- If you have to explain a big part of a function, then most probably the function is badly shaped / coded. Try to refactor.
- If there is already a place for a comment domain, then don't repeat that part in other places (eg: React js component arguments should be documented in propsType rather than @props).
- If you need to comment function arguments in Go then don't double info about argument type. It is already there (in a function declaration)! Proposed syntax: @arg-name description
// LoadConfig opens and parses a yaml application config. // @path principle path to read a config. If it's an empty string, // or it points to not existing place then it will try to read // config from "/etc/.../config.yaml" // @return error if I can't read or find a config file. func LoadConfig(path string) (config *yaml.File, err error)
Checklist
- Is the person submitting the code on the list of people who have confirmed transferral of copyright of code submitted?
- Am I having difficulty in understanding this code?
- Is there any complexity in the code which could be reduced by refactoring?
- Is the code well organized in a package structure which makes sense?
- Are the class names intuitive and is it obvious what they do?
- Are there any classes which are notably large?
- Are there any particularly long methods?
- Do all the method names seem clear and intuitive?
- Is the code well-documented?
- Does it follow common Java code conventions?
- Does the code submitted introduce unnecessary dependencies which reduces the modularity of the codebase?
- Are there ways in which this code could be made more efficient?
- Are exceptions simply swallowed anywhere, rather than being handled explicitly?
7. Deployments
Normally we deploy only the release branch, which should contain only validated and tested (all tests pass, manual regression tests pass) version from master branch. Deploy only using OPS Code tools (provisioning) and buildbox environment.FAQ
What is an Icebox?
Icebox is a place in our project management software where everybody can propose a task. It contains stories that have not yet been prioritized.On most of our projects, we find ourselves discovering new stories all the time, based on the continuous feedback loop that Tracker encourages. Not all stories end up in the backlog, but it’s liberating to be able to capture new ideas and user feedback as they occur. The downside of this is that the icebox, where all new and unprioritized stories live, can grow out of control very quickly. It’s not uncommon for longer lived, active projects to end up with hundreds, even thousands of stories on ice.
More information about it and related processes you can find in the Defrosting Your Icebox article.
Synchronizing: merge or rebase?
Read a great merge or rebase post by experienced people from Atlassian (the creators of bitbucket and tools for git and mercurial management). Summarizing:- Rebase by git pull --rebase when syncing shared feature branch (with others changes on that branch). You can make it default for pull by: git config branch.autosetuprebase always, but then remember to not use pull for different branches (you can use pull --no-rebase or simple fetch + merge)
- Merge when syncing with another branch. Don't use rebase for this (especially when you share the work)!
- Linus on git rebase: git pull.
When should I push my commits? What if I need to break in the middle?
Push when you finished your feature/mission or when you finished the logical part of a task. Normally you shouldn't push every commit update, unless you are working with someone. Having a lot of checkpoints might be good, but push only the good one (others just squash).When you need to switch machines, or stop in some unfinished shitty place and you are not certainly when/where you continue then you can always make a side branch feature-x-shit-y (treat it as a private branch) and push it. When you come back to continue when you can squash fixes and middle-in-the-shit checkpoints and rebase on the head of the feature branch. But it should be really rare - because the missions should be short.
It is an easy recipe for efficient workflow, where we can efficiently debug the history.
When can I commit directly to master?
You can commit directly to master when your change:- is small (eg fix, readme update, logging) which fits in a single commit, and
- doesn't change or bring new logic.
- you are sure you don't need backup.
- don't share the work with someone else.
If your change is small and fits in one commit than you can cherry-pick it from feature branch instead of merging.
Are you afraid that Git lost your commits?
That is not the case. git preserve the branch you were on until the rebase successfully completes. In the meantime you can always do agit rebase --abort to undo the rebase. After it commits, you can use git reflog to see all of the commits that were supposedly "lost" or "uncommitted" from any recent rebase (since the last garbage collection which for me is less than once a month). You can easily create a branch for any of those commits using git branch foo and look at it, switch to it, etc. I have NEVER lost a single commit doing a rebase after many years of using git heavily. When there are no conflicts (usually the case) then everything happens totally smoothly. When there is a conflict, either I easily resolve it or else I git rebase --abort and react to the kind of conflict I got such as reordering or squashing the commits using (git rebase --interactive). If several of my commits conflict, I may use git merge so that I only have to resolve conflicts once, in which case the noise in the history is worth it.
What is our branch naming convention?
[app_name]-[fix]-<update-description>
- [fix] - optional part when update is a bugfix
- number-17 - pretty task which touch all components (server, client)
- webclient-quoteNew-select2 - select2 implementation in quoteNew component in client
What to do when you can't find a settlement with a reviewer?
Call him or find other developers who will make a quorum.How to make review issues
While commenting / discussing a pull request we need to track what needs to be done to accept the pull request. Asana is our tool to track all tasks so it is reasonable to use it for review issues (issues from particular review) tracking.By adding a subtask to review task:
- a developer should set a high priority for this task (unless he is in the middle of other important things and don't want to be disturbed).
- we can see what lefts
- we can see why the main task is not complete yet
- it helps reviewers to accept the pull request (by tracking what lefts)
- it helps feature author to finish the pull request by prioritizing his tasks
What are non-blocking review comments?
When reviewer:- invades on some decision which is questionable to achieve or
- comments are not constructive
What is our filename convention?
For .go and .py files:- we use underscore to separate_words_in_filename.go
- test files have a _test suffix
- We use camelCase.js
- Test files have a test.js suffix
What is about code generation?
Some code is generated by a program. Example of such code generators:- grammar parsers
- enum printers (go stringer)
- documentation generators
- type generators
When to update a changelog?
Changelog (changelog.md) presents a broad outline of features changed / introduced in application. Whenever you make a new feature or make a significant feature modification - which will change a use case then you should include it in changelog before doing PR. We are not going to list all things there - these we have in the commit log.What next?
Become a ninja